<abbr id="uwuky"></abbr>
更新時間:2026-03-17 01:03:28
如若轉載,請注明出處:http://m.u1638.cn/product/46.html
PRODUCT
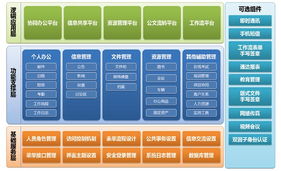
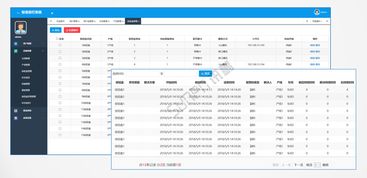
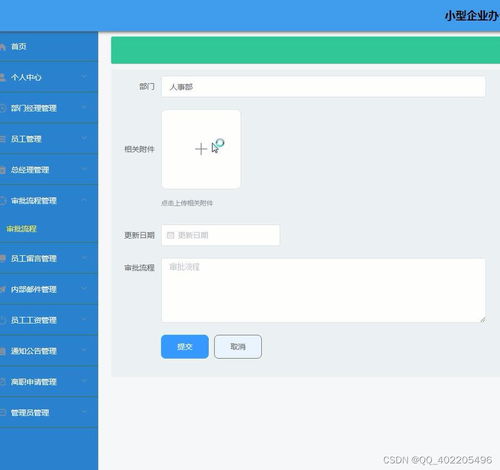
產品列表
更新時間:2026-03-17 15:41:57
更新時間:2026-03-17 05:42:18
更新時間:2026-03-17 03:27:24
更新時間:2026-03-17 11:10:23
更新時間:2026-03-17 04:13:11
更新時間:2026-03-17 14:55:22
更新時間:2026-03-17 15:06:24
更新時間:2026-03-17 10:53:47
更新時間:2026-03-17 23:46:08
更新時間:2026-03-17 05:31:44
地址:深圳市南山區舊粵海街道科技園社區科偉路9號科技園39區17棟310
電話:0755-73**
Copyright © 2026 m.u1638.cn 辦公管理系統 深圳斌士網絡科技有限公司 版權所有 Sitemap